2020.09.26 編修文章內容
2019.11.27 編輯文章格式。
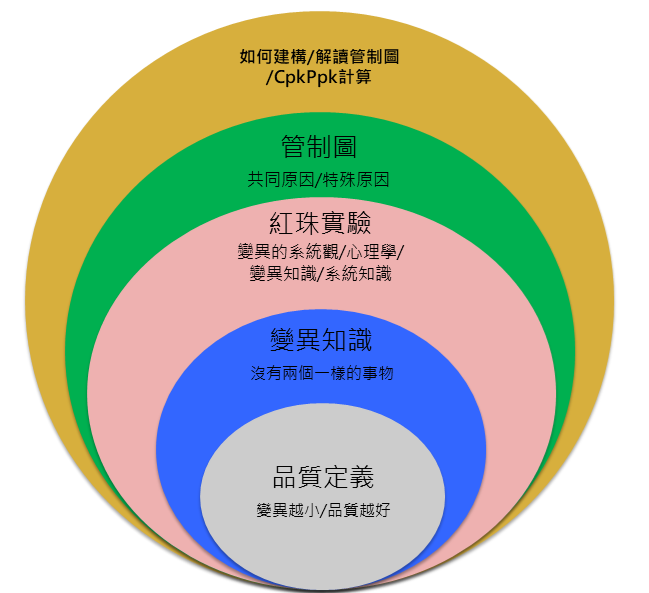
目錄
文章內容都是錯的SPC知識
工作狂人的網站寫過一篇文章討論Cpk及Ppk的計算演練「管制圖Cpk、Cp與Ppk、Pp的計算實例演練」,文章底下扣除我的留言總共有7篇留言,全都圍繞著作者文章提及的結論:”Ppk值幾乎永遠都大於Cpk值”
Jeff看到文章中的陳述以及各位讀者的討論,了解到在這部分的謬誤,因此開了一篇文章想澄清這部分的觀念以及完整陳述SPC應如何執行的細節,各位讀這篇文章時可以參照工作狂人原先的文章以及Jeff的這篇文章及參考文章。
讀者的留言
《留言1》
“Ppk值幾乎永遠都大於Cpk值” 我找到幾個資料和這說法相反,請看以下連結,
http://sixsigmastudyguide.com/process-capability-cp-cpk/
In theory Cpk will always be greater than or equal to Ppk. There are anomalies seen when the sample size is small and the data represents a short amount of time where estimating using R will overstate standard deviation and make Cpk smaller than Ppk.
而且你可以看以下連結中的minitab計算的實例,Cpk也是大於Ppk http://blog.minitab.com/blog/michelle-paret/process-capability-statistics-cpk-vs-ppk 這是因為樣本大小不同造成的嗎?? 再麻煩你開釋了,謝謝
《回應1 by Jeff》
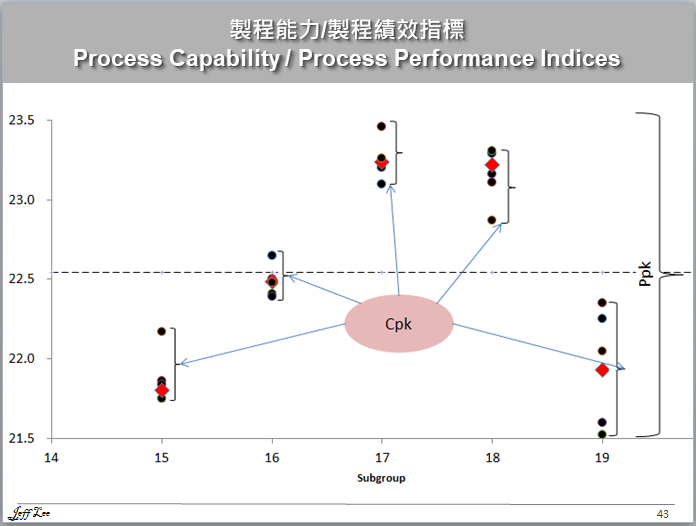
從Ppk跟Cpk的公式就能直接推導Cpk>=Ppk的結論,因此”Ppk值幾乎永遠都大於Cpk值”這句話本身就是錯的。由於作者本身的結論是錯誤的,所以讀者留言1感到困惑。事實上留言1的讀者找到的網址是正確的,但網址提到的狀況是例外中的例外,其實不值得詳談。簡單來說,如果你的SPC每組數據都有4~5筆,而且又有20~25組數據,那就不可能發生Cpk < Ppk的事情,那也就沒什麼好討論的了。
《留言2》
對於 Chen 的留言我的想法是因為定義來說ppk是看overall變異,所以理論上的確overall >= within 所以 Cpk >= Ppk,但是當製程趨於穩定時overall ≒ within Cpk ≒ Ppk,又因為有抽樣誤差,因此有可能 Cpk < Ppk 不知道這樣對不對@@
《回應2 by Jeff》
這樣的推論是不正確的。製程趨於穩定的時候,總變異=組間變異+組內變異;此時由於製程穩定,所以組間變異只能說很小,不能說等於0。在這個條件下總變異仍然會大於組內變異,因此Cpk仍會>=Ppk。
《留言3》
你好!首先謝謝你的文章,個人受益良多!謝謝。小弟對這篇文章有一行計算”標準差平均值(s-bar)=0.034436″感到疑惑,這5組標準差(0.0334、0.0414、0.0361、0.0268、0.0344)不應該是”0.03442″嗎? 文章中0.034436是如何計算出呢?
《回應3 by Jeff》
由於作者將20組、每組各5筆數據誤認成5組、每組各20筆數據,因此導致有這5組標準差。所以這5組標準差是錯誤的資訊,不需要糾結到底是怎麼計算的,因為怎麼算都是錯的。
《留言4》
我想,不管是cpk、ppk,式子裏頭的未知參數都用相對之估計式取代,然估計式可以試點估計或區間估計法,是故CPK, PPK應以其區間估計值(信賴區間)來看待(考量抽樣誤差)而非僅單一數值。理論上還是 CPK>= PPK。
《回應4 by Jeff》
這位讀者想得太複雜了,居然還用上了區間估計…。事實上沒那麼複雜,在SPC裡面我們就是運用點估計的方式取得母體標準差的估計值,所以結論還是一樣,Cpk會大於等於Ppk。
《留言5》
你的計算是對的。但最後的結論是不符合一般狀況的,其實一般都是Cpk>=Ppk。因為總體標準差=組內標準差+組間標準差,Cpk只有考慮組內標準差,所以Cpk會比較好看。你會有這個結論是因為文中的範例太特殊,這個範例中,組內標準差太大,而組間差異幾乎等於0,才會導致Ppk>Cpk的特殊結果。我猜你是用亂數產生器去跑100個數字,然後分成5組,所以數據才會長這個樣子。
《回應5 by Jeff》
這位讀者說的總體標準差=組內標準差+組間標準差 是錯誤的說法,正確的說法是總變異=組內變異+組間變異 差別在於有無平方項。平方項的概念是取距離的總和 因為想評估資料之間彼此的距離遠近又擔心正負相抵,因此提出了平方項相加的概念 作為評估資料之間的距離關係,另外並非這個範例太特殊 純粹就是作者本身用錯計算方式了
上述這段我說錯了,這位讀者前半段說的是對的,總體標準差=組內標準差+組間標準差。但後面的猜測是錯的,作者不是用亂數產生器跑100筆資料,而是算錯了數據的組數。
《留言6》
Subgroup sizes=5,感覺是每組有5筆(5筆*20組),而不是有5組(20筆*5組)。
《回應6 by Jeff》
這位讀者說對了,但還不是很確定的感覺。其實不用擔心,就是因為作者算錯數據了,你的觀察是正確的。
正確的知識應該被更多人看見
截至2020/09/26為止,工作狂人這篇錯誤的文章已經有45,800人次看過,Jeff也已留言更正但文章內容仍然沒有更動,錯誤的知識仍然被更多的人看見。而Jeff這篇文章目前的閱覽人次是2,800次,相差約16倍。我期待未來的日子Jeff的這篇文章閱覽人次能逐漸超越工作狂人那篇錯誤的文章,以糾正大家錯誤的知識及觀念。
正確的知識有其必要性,正確應用知識能協助各位在工作中以簡化繁,真正理解問題所在;一知半解甚至似懂非懂的胡亂應用只會把問題越弄越糟,大家領薪水瞎忙一場,沒有任何人得到好處。
參考文章
【品質工程】為什麼Cpk會引發誤導?
【品質工程】好的Cpk就表示製程能力就一定好? 那可未必
【品質工程】從IATF16949車用五大核心工具PPAP和SPC手冊談Ppk與Cpk的差異
【品質工程】IATF 16949 SPC Manual 為什麼Cpk >= 1.33會引發誤導?
【品質工程】SPC管制圖Cpk >= 1.33有兩種計算公式,使用時機跟差異在哪?
【品質工程】為什麼Cpk >= 1.33才算好 ? 1.33這數字怎麼來的?
【品質工程】SPC為何要「組內變異」最小、「組間變異」最大? SPC的抽樣原理
【品質工程】為什麼SPC Control Chart要先看R chart or S chart ?
我再補充說明一下, 這位讀者問說Cpk既然大於等於Ppk, 那為何通常會要求Ppk>1.66, Cpk>1.33?
這單純是因為這位讀者將一般業界的要求與Cpk&Ppk的關係搞混了
簡單來說在同一個製程當中, Cpk一定會大於等於Ppk的, 這是公式計算的結果不可能有問題;而Ppk要求大於1.66及Cpk大於1.33的事情則是不可能同時發生的, 勢必在公司內部對這些指標有誤解
你好, 我在猜這是業界自己發明的規則吧
業界通常會發展出一些很奇怪的方法, 我聽過的是Ppk用於新產品階段, Cpk用於量產品階段
但實際上當我們在評估一個製程的時候, 不應該去計較那到底是新產品還是量產品, 而應該去關心該製程到底穩不穩定. 一個穩定的製程應該透過Cpk, Ppk, Cp, Pp一起觀察才對
謝謝您的分享,還在研讀中
想請問如果CPK>=PPK
為甚麼通常PPK要求1.66以上
CPK只需要1.33