目錄
統計製程管制Statistical Process Control的發展
統計製程管制原文為Statistical Process Control,源自於蕭華特博士的發明。這項發明的意義重大,為現在的工業界建立了品質管控的基礎,徹底提升業界管控變異的能力。這項發明同時也受益於戴明博士的繼承與推廣,並且協助日本在戰後成為高品質的代名詞,於是目前我們所熟知的SPC成為了工業界及管理界的利器;SPC後來甚至在車用領域的品質系統IATF16949中被定義成核心五項工具之一,可見得SPC在品質工程領域佔了一席之地。
但即便在戴明博士的年代,他也已經注意到SPC被視為僅能用於工業界製造業的工具,他提醒這樣的觀點與觀念是不對的,SPC同樣也能大量用於管理學上。
SPC特別強調共同原因Common Cause及特殊原因Special Cause,也就是說共同原因使得SPC產生一般性的隨機波動,而這種波動是極難去除的。當SPC維持這種狀態,我們就說它處於穩定狀態;相反的,假如有特殊原因產生 SPC就會產生不隨機的波動,因而超出管制界限或者呈現某種趨勢,所以如果我們若想要找出某項參數是否在過程中出現變化,就能夠使用SPC作為監測的工具。
一般常見的SPC有X-bar R chart、X-bar S chart、p- chart、np-chart等等。近年來由於不同的目的陸續發展出其他SPC,不過它們彼此之間的原理大致相同,因此在本文中只會介紹到X-bar R chart、P- chart、np-chart 並不會提及更多其他管制圖。
而SPC主要由管制中心、管制上限和管制下限所組成,其計算方式依循統計原理我們將在下方一一介紹。
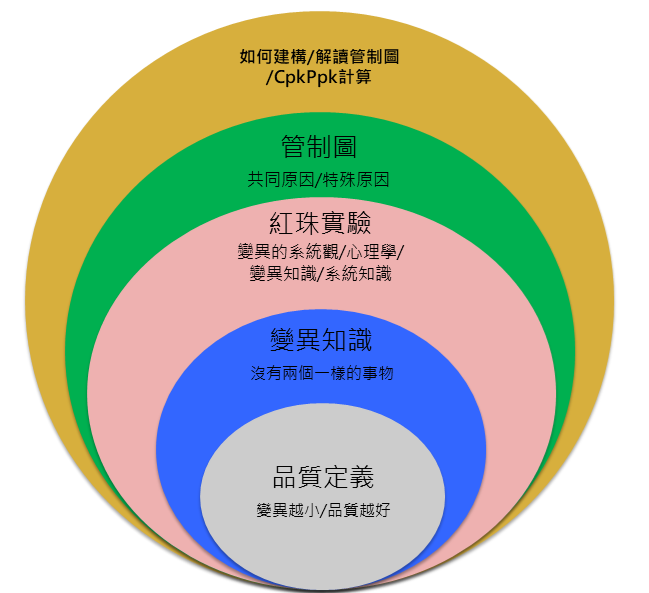
品質的定義
「品質」有許多面向的定義 品質工程教科書提到許多專家提及品質的面向,包括顧客滿意度、可靠度、外觀精緻度、尺寸公差等等,或者將品質定義為「符合規格」、「符合顧客需求」,但這些定義都沒有「品質是變異的反比」這句話來得精準、確切。在此定義之下 品質從一個抽象名詞成為一項具有可操作定義的具體產物,其中「變異」兩字 是任何學習統計或品質管理的人都應該具備的觀念,而現代品質工程用來描述變異的工具就是機率與統計。
透過機率與統計這兩項工具可以清楚量化產品品質特性,包括濃度、尺寸、角度、比例、個數、速度、溫度、彈性、硬度等量化指標都能夠適用。甚至包括質化指標,透過客戶較注重的模糊概念轉換成質化數值也可以適用機率與統計,從此之後變異就能與品質完美的結合,成為我們評估品質好壞的標準。
蕭華特博士基於統計學的基礎發現常態分配以及假設檢定可以用作描繪管制圖,基於常態分配的參數與分配特性,平均值正負3個標準差之內的比例約為99.73%,並且認定在隨機抽樣的前提下,抽出的樣本平均值會落在3個標準差之內的機會也是99.73%;若抽出的樣本平均值落在3個標準差之外,就透過假設檢定傾向認為此平均值超出管控。
超出管控的樣本值被視為不具統計的隨機性,也就是蕭華特博士所稱的”Assignable Cause”在背後作祟,導致樣本產生不隨機的變異。戴明博士則改稱為”Special Cause”特殊原因,表示有特定的因素影響。管制圖就以這樣簡潔的構想開始建立並且成為監控品質特性的重要工具,以下進一步說明管制圖的統計基礎及使用情境。
中央極限定理(Central Limit Theorem)
中央極限定理(Central Limit Theorem)的數學模式很複雜,卻能用很直觀的工具觀察。定義:「無論隨機變數的原始分配為何,其樣本平均數在樣本數n夠大時會呈現常態分配。」其常態分配的參數為平均值mu,變異數 sigma^2/n。(事實上不限定於樣本平均值,而是隨機樣本的線性組合都會服從常態分配。)
這件事太重要了,也讓我們在使用SPC的時候可以先忽略隨機變數的原始分配。SPC的每一個樣本點是由m個樣本為一組算出樣本平均值(一般小於10,不然會量測太久),持續執行n組(通常n>30) 此時m個n組計算出的總樣本平均值就會大略具備常態分配的型態,讀者也可以從Galton Board看到鋼珠落下後呈現常態分配的樣貌。鋼珠原先服從二項分配(每一次撞擊釘子視同往左或往右選擇),而落下的過程經過十幾道選擇,便逐漸從二項分配成為了常態分配。由於此過程非常直觀,因此即便不具備統計背景的使用者也能完全了解此定理。

常態分配
中央極限定理的存在使常態分配成為自然界也是實務界最常見的分配,常態分配具備兩項參數,分別是平均值與變異數。當這兩個參數被唯一決定時,常態分配的型態也被唯一決定,反之亦然(若且惟若)。常態分配在外觀上類似倒鐘形狀,因此又被稱作鐘形分配(Bell-shaped Curve)。
如上文所述,無論是哪一個常態分配,其平均值正負3個標準差之內的曲線面積占總面積99.73%。如此高的比例讓我們相信只要隨機變數呈現常態分配,其抽樣結果勢必會有大部分資料落在平均數正負3個標準差之內(99.73%) 僅有0.27%例外。這項特性再結合中央極限定理讓我們知道大部分的樣本平均值會落在3個標準差之內,因此如果被我們抽出0.27%的結果,我們就會傾向相信這個結果應該不是由原始的變數產生的,而可能是由已經產生變異的變數所產生的,這也就是假設檢定的原理。仔細想想這些方法還真是聰明的發現。

假設檢定
假設檢定其實是根據理則學(邏輯推論)所產生的判斷方式,其方法很簡單;根據高一數學第一章:若P則Q = 若非Q則非P。白話文就是若下雨(P)則地板濕(Q),若地板沒濕(非Q)就代表沒下雨(非P),但是若下雨則地板濕,不代表若地板濕則下雨。大家可以再回想一下這部分的邏輯思考。
根據常態分配,由於大部分的樣本平均數都落在平均值正負3個標準差之內,也就代表以下邏輯:
若抽樣發現樣本平均值落在平均值正負3個標準差之內,則相信此樣本平均屬於此常態分配;
若此樣本平均不屬於此常態分配,則相信樣本平均值落在平均值正負3個標準差之外。
事實上假設檢定也與法律上的無罪推論相關,所謂的無罪推論是假設嫌疑人沒有犯罪,再透過蒐集證據的方式證明此人有犯罪。這樣的觀點主要是因為世界上大部分的人都沒有犯罪,犯罪的人是少數人,所以使用無罪推論可以讓無罪的人被判有罪的機率降到很低;但是如果這世界犯罪的人很多,那就不能使用無罪推論,這件事情一定要特別注意。
在使用SPC的過程中,我們會觀察每一個樣本平均值是否落在管制界限之內,若樣本平均值落在管制界限之外,我們就傾向於相信這些樣本不是來自於原始的分配。原因是抽樣抽到管制界限之外的機率約為0.27%,我們認為不容易抽到這種情況。這個分配可能是機台參數、骰子的點數或者檢驗錯誤的比例,因此樣本平均值超出管制界限背後代表的可能是機台參數偏移、骰子點數被動手腳。
統計製程管制的使用
上述的中央極限定理、常態分配及假設檢定就形成了SPC的主要架構,另外還有一項統計工具叫做「估計」,使用時機是在抽樣時用樣本觀察值推估母體參數;在計算管制界限的過程中會以全距和樣本標準差估計母體標準差,不過這對於理解SPC整體的架構沒有太大影響,所以在此我們忽略不提。
SPC的使用很簡單 以下透過我自行撰寫的骰子點數Excel VBA來進行說明,想要取得檔案的人可以透過google雲端硬碟自行下載。
這個SPC小遊戲主要是藉由5顆骰子所骰出的點數來說明骰子平均數的分配狀況,5顆骰子的點數預設值是6,代表骰子點數從1點到6點;但這個骰子點數是可以調整的,遊戲者可以自由調整骰子參數從1調整到10,代表骰子可以從1~1點或者1~10點。
圖一是骰子遊戲進行到第10回合的狀況,此時5顆骰子的點數都是1~6點的正常值。
可以看到此時每一回合的骰子點數平均值落在2~5.2,其平均值為3.62。


圖一
從11回合開始我們將骰子調整為1~10點,此時每回合的骰子平均值3.8~6.6
從20回合開始我們將骰子調整為1~3點的參數,此時每回合的骰子平均值從1~2.4


圖二
這些調整可以從X-bar chart上看出端倪,中間的部分似乎有往上攀升的趨勢,而最後一段似乎有向下降低的趨勢 ;且在圖三第11、第17、第18、第25點都超出了管制界限。
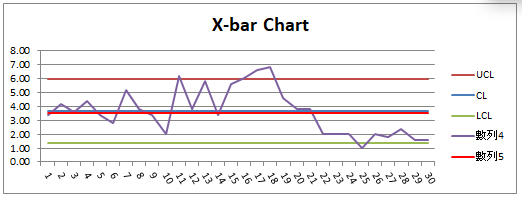
圖三
R-chart也有相同的情況發生。圖四在第16、第17、第20點有超出管制界限的情況。

圖四
由於骰子的點數在30回合之中被我們設置了三種狀態,所以整個管制圖看起來充滿波折。
事實上這種線段看起來就”不隨機”,也就是說背後一定有什麼問題在干擾骰子;當然我們已經知道骰子的點數被調動了兩次,因此具備了三種狀態,所以我們很容易就能理解SPC管制圖所代表的含意。
然而實務上我們並不知道機台發生了什麼問題,或者那些因子在干擾著我們,也因此SPC是一項觀察工具,透過SPC我們能觀察到因子的變異,然後再用工程方法解決。
結論
如何跟沒有統計背景或觀念的人講解SPC是推廣SPC的過程中最困難的部分。也因此本文在說明的過程之中省略掉許多統計的演算過程,但這不代表統計在SPC的教學過程之中可以忽略,而是視狀況挑選較容易接受的方式講解。
許多具備數學統計的推算往往可以用直觀的教具說明,進而達到眼見為憑的吸收效果,這或許是在業界及學界的另一種教學方法,而我認為這方法值得推廣。
因為我們最重要的目的在於讓更多人能夠使用SPC,進而利用SPC協助降低產品變異,就可以讓台灣各個業界提升他們的品質水準同時降低成本。
瀏覽次數:1272
Hi Jeff,
謝謝您雙十節收假前的回覆,經過您的說明,原來是我觀念需要調整。我一直以為兩者可以分開看也可以獨立看。通常製作PPAP會要求CPK能力超過1.33就算是PASS了(此時需取樣30pcs以上樣品來跑CPK),所以才會有那樣子的疑問產生。另外CPK的重點是要常態分配,30pcs以上就已經是達到常態分配的條件了對嗎?
綜合您的說明:
1. CPK是需在SPC管制圖完成後確認的,並無法單獨解讀
2. 接續以上使用m=5, N>20,就是說至少會有100個樣品,此時應該使用這100個數據跑CPK?(如同"如何使用SPC制定產品參數規格"一文)
3. PPAP的CPK確認也應該FOLLOW上述步驟?
4. 30pcs的樣品數開始有常態分配的趨勢是對的嗎? (我記得绿帶好像有提到)
5. 假設4是對的也不能單獨計算CPK在SPC沒有確認穩定之前,這樣描述對嗎?也就是說我們一般準備要量產時(PPAP時)抓了某個尺寸(30pcs up,但沒確認SPC)要達到CPK1.33就算PASS,這個動做是錯誤的嗎?
不好意思問題有點多,感謝Jeff版主不吝指教,或是有建議的文章可以閱讀嗎? 感謝您
Hi JP,
抱歉我最近在移轉Blogger到Wordpress, 回得慢了請見諒
1. 理論上是的
2. 理論上是的
3. 理論上是的
4. 統計中的抽樣是有所謂小樣本的說法, 一般認定N >= 20即為小樣本, 但這跟常態分配與否無關
但在統計中還有一個定理叫做CLT中央極限定理, 講的就是”任何分配的期望值, 在樣本數越大的狀況下, 會越接近常態分配”
在SPC裡面我們就是利用中央極限定理在做X-bar的常態分配, 在N>=20時, 我們認定此SPC應該要具備基本的常態分配樣貌
關於中央極限定理可以參考以下網址 https://statistical-engineering.com/clt-summary/clt-uniform-distribution/
5. 在沒有SPC之前去計算Cpk都是沒有意義的, 只要牢記這一點就好了, 原因是某些SPC的錯誤型態會讓明明有問題的SPC產出很棒的Cpk數值, 這很不合邏輯卻是業界時常發生的事情
Hi JP,
感謝你的提問, 我簡單釐清一下觀念:
1. m=5, N>20這部分沒問題
2. 建立完SPC的Control Chart並確認管制圖的常態性之後計算Cpk才有意義
3. 綜合以上兩點, 並沒有所謂Cpk計算須要取30個樣品就為常態分配的狀況, 我並不清楚這類的說法來原為何?
原則上Cpk提供的是建立完Control Chart之後進一步確認該管制圖的數值工具, 前提是SPC建立的步驟要正確
希望有回答到你的問題!!
Hi Jeff
最近看了您的許多文章受益良多,先跟您說聲感謝。這篇的討論有提到m=5, N>20大概就可以看出常態分配,您的另一篇文章"如何使用SPC制定產品參數規格"的一文也寫到需100個樣品以上,也就是一様m=5, N>20。綜合上述就大約需要100個樣品,但我們在計算CPK取30個樣品的原因也是因為30pcs以上樣品就為常態分佈,如果我們要討論CPK跟SPC的話,抽樣要符合常態分配個沒有問題,但需要多少樣品這件事讓我有點混淆,想請教Jeff的專業見解。謝謝您!
你好,
謝謝你的留言, 網路上有許多模擬器可以參考, 像是下列網址https://www.geogebra.org/m/UsoH4eNl
我剛剛玩了一下大概m=2的條件下, 100次就可看出是常態分配曲線
實務上的常態分配認定是很寬鬆的, 只要直方圖看起來沒有雙峰或者偏態就可以了, 即便使用常態檢定其認定條件也是相當寬鬆的
回到問題本身, 骰子的分配是Uniform分配, 本身與常態分配差異極大, 自然需要較多次數才能呈現常態分配了
我自己寫的Excel VBA骰子遊戲則是設定m=5的狀況去玩, 在n>20之後很容易就看出X-bar呈現常態分配了
Jeff您好
我是2021年6月20日 下午11:19匿名留言的觀眾
謝謝您的回覆
我在m=2的情況用骰子實驗去做模擬跑了5000筆資料
跑出來確實是成鐘型
但離常態分配還有一點差異(已用統計檢定確認過)
以中央極限定理來說是m>30才符合
我也理解現實層面不可能
但市面上大多教科書還是照常使用3倍標準差去畫管制圖
我找到的文獻解釋如下 : (https://www.spcforexcel.com/knowledge/control-chart-basics/control-charts-and-central-limit-theorem)
Walter Shewhart, the father of SPC, used three sigma limits for control charts. But it was not because of the central limit theorem and the data being normally distributed. It was because that ± three sigma will contain the vast majority of the data regardless of the shape of the population’s distribution.
簡單說就是無論何種分配下,3倍標準差內的資料仍佔多數
但就我提到m=2的骰子例子而言
UCL>>6且LCL<<0
會造成永遠不alarm的問題
目前我仍在思考中
也謝謝您這麼快回覆我的問題
匿名你好,
m=1確實無法形成常態分配, 也如你提到的骰子實驗, 在m=1時只會是正常擲骰子的點數分配狀況~U[1, 6]
但只要m>2以上, 形成了樣本平均數(其實應該定義為樣本的線性組合), 然後在n>30的條件下會很近似常態分配
在m=2的情形之下, n可能要大於50才有機會形成常態分配;
在m=5的情形之下, n大概只要30就可以看到常態分配的樣貌了;
實務上m很少大於5, 主要的原因如我所說, 因為量測時間也是一種成本, 量測過多不是一件好事
您好,關於文章有一段想請教一下:
“SPC的每一個樣本點是由m個樣本為一組算出樣本平均值(一般小於10,不然會量測太久),持續執行n組(通常n>30) 此時m個n組計算出的總樣本平均值就會大略具備常態分配的型態”
我的認知是m>30才符合中央極限定理的定義是嗎?
舉例來說,擲骰子實驗,m=1,很直觀的n不管多少都會是1~6點會平均分佈,不符合常態分配
但我看很多SPC的書上m幾乎都在10以內,但管制圖卻行之有年,請問我的理解哪裡有盲點?
謝謝
匿名你好,
所謂的資料要呈現常態分佈, 指的是經過平均後的資料, 箇中的原理可以參考中央極限定理;複雜的我們也不用懂太多, 只要知道無論原始資料的分布狀況為何, 其資料的平均數在次數越多的情況下, 會趨向常態分配。
一般來說你很難觀察到原始數據會呈現常態分配, 就算是, 你也很難在SPC的數次抽樣裡面觀察到;因此對SPC X-bar R chart來說, 都是在討論樣本平均數是否為常態分配。
希望有回答到你的問題。
目前正在學習SPC,這裡的文章受益良多,感謝~!
想請教一些問題,要計算製程能力時(Pp, Ppk, Cp, Cpk),需要製程是管制狀態、資料呈常態分配等。
關於資料要呈常態分佈,此資料是指抽樣分群後的平均數資料點,還是指各個資料點?
如使用Minitab時,是針對原始資料點,若檢定為非常態則要使用其他分配model再計算製程能力,有些講義則是針對平均數來檢定是否為常態,想向Jeff請向此部分。
謝謝, 請多多指教
網路無意間搜尋到您的文章, 很隨機, 很受用, 感恩~